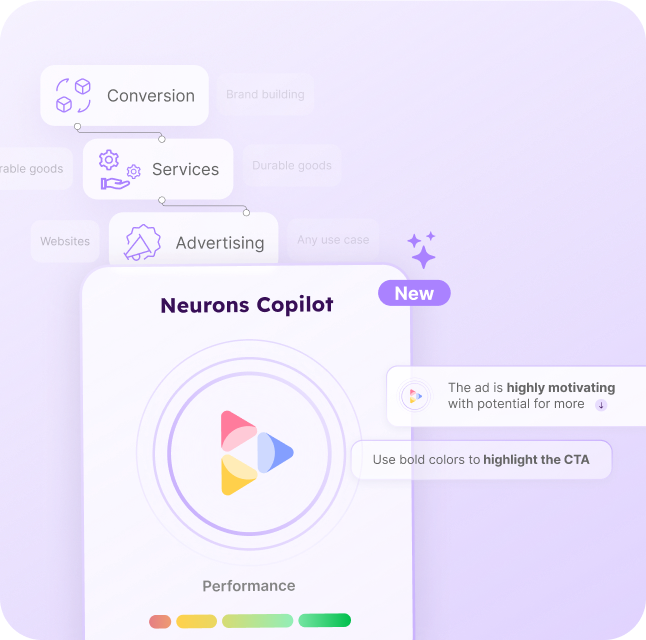
Build unforgettable campaigns with the only AI copilot built on neuroscience.

Years of neuroscience experience
Images processed
Datapoints

















Get personalized recommendations and fine-tune ads based on your industry, platform, & more

Get rapid feedback on your visuals, and optimize ads with fast AI recommendations.
Tap into 20+ years of neuroscience research with the only AI copilot built on neuroscience.


Visualize audience attention instantly. See what your customers see - before they see it.
Understand how much attention is on your key elements, draw custom areas of interest, or simply use Neurons’ automatic AOIs.


Predict how customers respond to your ads to make data-driven design decisions.
See how your ads stack up against industry standards, identify performance gaps, and make adjustments on the fly.


Compare your best designs side-by-side.
Choose the winning variation based on performance rather than intuition & put numbers to your creative choices.




SCIENTIFIC VALIDITY
Scientific validity is at the heart of everything we do at Neurons. Our methods and metrics are built on the latest approaches and cutting-edge advances in cognitive neuroscience, machine learning, AI, and psychology.

.png)